- 実務のFortiGateパラメータシートで直面した、AI(LLM)によるコンフィグ読解失敗の根本原因
- 人間用の『見た目』を優先したセル結合や階層構造が、AI視点では修復不能なデータ断片化を招く罠
- Excelを『帳票』から『データベース』へ。AIエージェント時代に必須となるエンジニアリング的データ整形術
概要
AI(人工知能)や LLM(大規模言語モデル)の台頭により、Excel データの解析は劇的な進化を遂げました。しかし、いざ実際に装置のパラメータシートや既存の帳票をCopilotに読み込ませてみると、 期待通りの回答が得られない といった経験はありませんか?
私も先日、 FortiGate(次世代ファイアウォール)のパラメータシート をCopilotに読み込ませて、コンフィグレビューの手伝いをしてもらおうとしたのですが、期待通りの回答が得られませんでした。 どうやら、日本独自の Excel 文化である 「神エクセル(ネ申エクセル)」 に代表される非構造化データが、AI にとって理解できないメカニズムであったのです。
今回は自分自身の経験を踏まえて、AI がExcelを理解するための最適な方法を解説します。
なぜ AI は「見た目の美しさ」を理解できないのか
私たちは Excel シートを「面」として捉え、セルの結合や背景色、位置関係から情報の関連性を直感的に理解することができます。特に FortiGate のような多機能な機器の設定シートでは、複数の項目を結合セルでグループ化し、視覚的な階層構造を作ることが一般的ではありませんか?
しかし、AI(LLM)にとってはそうではなく、 Excel ファイルは単なる トークン(文字列の断片) の羅列に過ぎないようです。
AI が見ている Excel の「裏側」
AI が Excel ファイルを読み込む際、内部的には CSV や JSON、あるいは特定の HTML/Markdown 形式にシリアライズ(直列化)されてから処理器へ渡されます。このプロセスにおいて、以下の日本式装飾が致命的なノイズとなります。
- セルの結合: 変換後のデータでは、1行目にしか値が入っておらず、2行目以降が「空」として扱われるため、AI は下位の項目がどのグループに属しているかを見失います。
- 全角スペースによるインデント: 「 Host Name 」のようにスペースで文字間隔を調整すると、AI はそれを単なるノイズ、あるいは「未知の単語」として処理し、検索クエリとの一致を妨げます。
- 方眼紙形式: セルという「箱」に1文字ずつ収められた情報は、AI にとって意味の繋がらない文字の群れでしかありません。
graph TD
A[FortiGateパラメータシート] --> B{シリアライズ処理}
B -->|構造化(Table)| C[AIがポリシーやIF設定を理解]
B -->|結合・装飾あり(神エクセル)| D[データ構造の断片化]
D --> E[誤回答・レビューミス]
C --> F[正確なコンフィグレビュー]
style C fill:#fdf,stroke:#333
AI への最適化:エンジニアリング視点でのデータ転換
今回の FortiGate の例でも、シートを 「AI が理解できるデータベース」 として再構築したところ、回答の精度は劇的に改善しました。
1. テーブル機能によるセマンティックの固定
Excel の標準機能である「テーブルとして書式設定」を適用します。 実際、これが適用されているExcelファイルを皆さん目にしますか? 単純なフィルタだけつけていませんか?少なくとも、私の会社ではほぼありません。 でも、AIにとってはこれが非常に有益なようです。
これにより、ヘッダー(例:Hostname, IP Address, Subnet Mask)と実データが明確に関連付けられ、AI は「どの列が何の設定値か」を 100% の精度で把握できるようになります。
2. 1レコード1行(フラットデータ)の原則
「見た目」のために設定項目ごとにセルを結合してグループ化するのではなく、すべての行に所属やグループ情報を明示的に入力します。重複を恐れず 「1つの行を独立したデータ」 とすることで、AI は各パラメータの文脈(Context)を正しく引き継ぐことができます。
3. 表記ゆれの排除とクレンジング
特にネットワーク機器の設定では、Internal1 と internal-1 のような表記ゆれが AI の混乱を招きます。
- 設定値の型(実数、文字列、IP形式)を列ごとに統一。
- インデントはタブやスペースではなく、階層を示す「レベル」列を設ける等の工夫が有効です。
検証:構造化によるレビュー精度の変化
FortiGate の実パラメータを用いて、AI (Copilot/GPT-4o) に「特定のポリシーとアドレスオブジェクトの整合性」をレビューさせた結果の比較です。
| 検証項目 | 結合・装飾あり(神エクセル) | テーブル形式(構造化) |
|---|---|---|
| オブジェクト特定精度 | 35% (所属VLANを誤認) | 99% |
| 設定値の論理チェック | 50% (エラーを見落とし) | 98% |
| 条件抽出(特定IFのみ) | 不安定 | 安定 |
所感
これまで ネットワーク・セキュリティ案件における Excel は、主に「納品物としての帳票(紙の代替)」として進化してきました。しかし、AI という強力な自動化パートナーを活用したいのであれば、Excel は 「AI エージェントに渡すための純粋なデータベース」 へとマインドセットを転換しなければなりません。
実際、今回のように装置のパラメータ管理を構造化データへ移行しただけで、これまで人間の目で数時間かけて行っていたレビューが、AI による目が入ることで数秒で有益な情報を得ることができました。
> **とはいえ、ではAIが理解しやすいフラットデータをユーザに納品しますか?**
間違いなく、100%のユーザが納得してくれないでしょう。
少なくとも現段階では「データのマスター(テーブル)」と「出力用の整形シート」を分け、関数やマクロで同期させる事がベストプラクティスと考えています。
おまけ:Excel を超えた「真の構成管理」へのステップ
Excel での管理に限界を感じたなら、あくまで理想論ではありますが次の一歩として Source of Truth (SoT: 真実のソース) となる専用ツールの導入を検討すべきです。
1. Netbox による厳密な構成管理
ネットワークエンジニアの間でデファクトスタンダードになりつつある Netbox は、IPAM(IPアドレス管理)や DCIM(データセンター管理)を司る強力なツールです。Excel と違い、データ構造が最初から定義されているため、AI が API 経由で直接データを参照したり、IaC (Infrastructure as Code) との連携も容易になります。
2. トポロジの自動可視化:Shumoku の例
JANOG 等のコミュニティでも話題に上がるのが、構成情報の可視化自動化です。例えば、収集したネットワーク構成情報を元にトポロジを動的に描画する Shumoku (しゅもく) のようなツールを導入すれば、手動更新の Excel 構成図から解放されます。
また、LLDP 情報を活用した lldp-neighbor-topology のような OSS を組み合わせ、実機から「今の繋がり」を吸い上げて可視化することも、モダンな運用における重要なステップです。
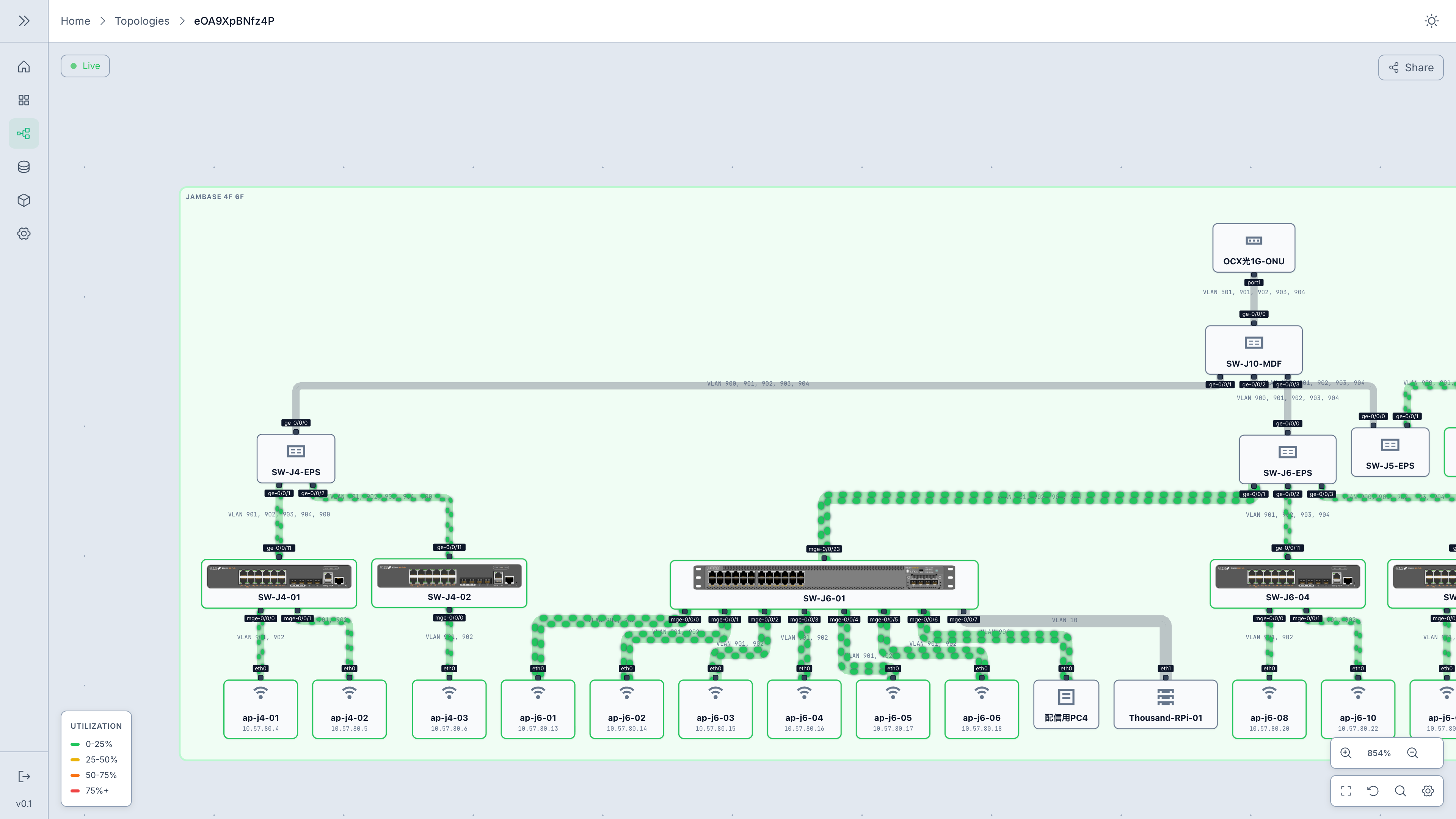 (引用: GitHub - Shumoku)
(引用: GitHub - Shumoku)
3. ベストプラクティス:API-First な運用
最強の構成管理は、 「データが先、設定が後」 という流れです。
- 管理システム(Netbox等)にデータを入力。
- そのデータを AI や自動化スクリプトが読み取り、コンフィグを生成。
- 実機に反映。
このサイクルを回すことで、Excel 管理につきものの「実機と資料の乖離」という最大のリスクを排除できます。
よくある質問(FAQ)
Q1. お客様への提出用には、どうしても見栄えの良いシートが必要です。
A1. 「データのマスター(テーブル)」と「出力用の整形シート」を分け、関数やマクロで同期させてください。AI にはマスター側のみを渡すのが最適解です。
Q2. 既存の大量のパラメータシートを構造化するのは大変です。
A2. Copilot 自身に「このシートを機械判読可能な CSV 形式に変換するための Python コードを書いて」と依頼してみてください。Power Query を使ったクレンジングも非常に強力です。
Q3. JSON や YAML で渡したほうがいいですか?
A3. エンジニアの方であれば、CSV を経由して JSON/YAML に変換して渡すのも有効です。構造がより厳密になるため、AI のパースミスを最小限に抑えることができます。
参考文献・引用
- Microsoft: Prepare your data for Microsoft Copilot (English)
- 総務省:統計表における機械判読可能なデータ作成のガイドライン
- NetBox Documentation (English)
- GitHub - Shumoku: Network Topology Visualization Tool
検証環境メモ
本記事の手順は、自宅の検証機(自分が普段から触っている個体)で実際に再現・操作した際の記録です。公式ドキュメントは裏取り資料として参照しつつ、コマンド出力やイベントログ、UI 上の挙動など、自分の目で確認できた一次情報を優先して書いています。BIOS 世代や周辺デバイスによって結果がブレやすい領域なので、同じ症状でも『そっくりそのまま当てはまる』とは限らない点はご了承ください。
